运行环境:python 3.6.0
"""
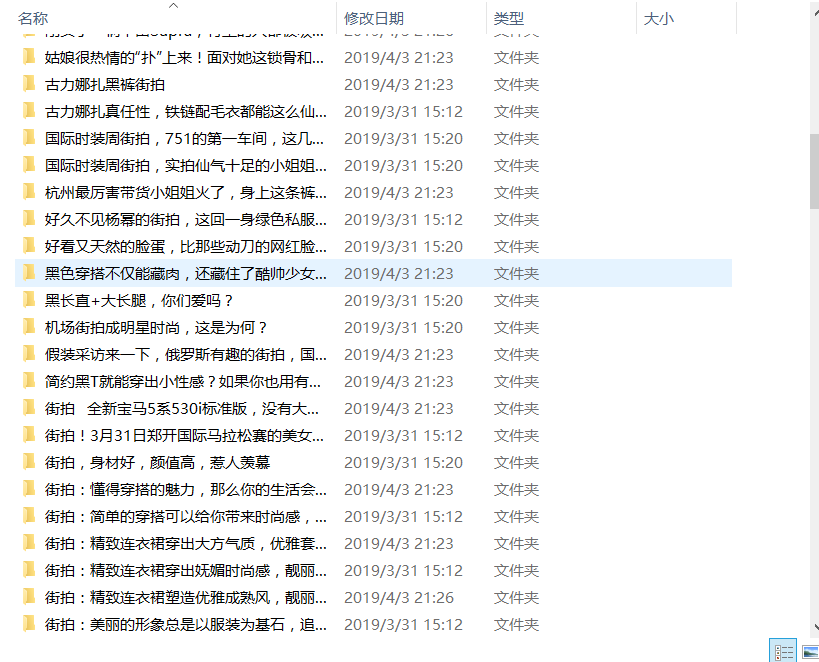
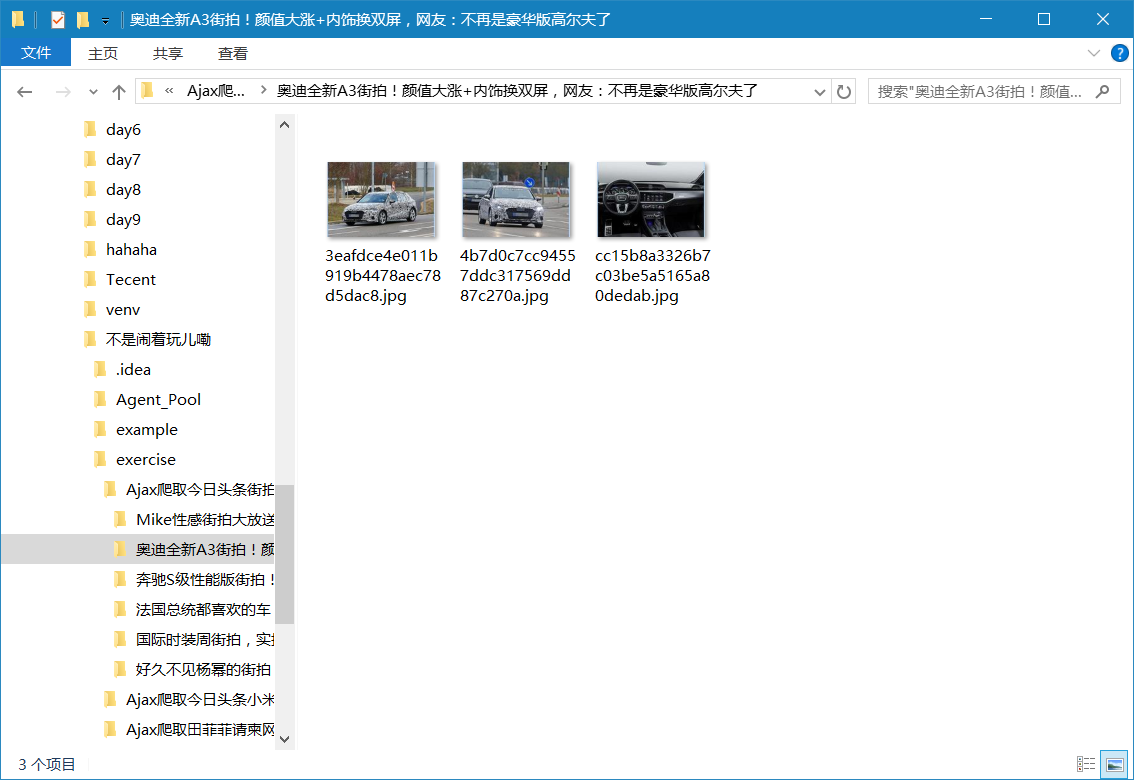
抓取今日头条街拍美图,然后抓取到的图片去重后分类存放
为了加快效率启动了多进程
"""
import requests
from urllib.parse import urlencode
import os
from hashlib import md5
from multiprocessing.pool import Pool
# 在创建二级目录的时候替换掉不合法的字符
table = {ord(f): ord(t) for f, t in zip(
'\/:*?"<>|',
' ')}
def get_page(search_keywords, offset):
"""
拿到网页源码
:param search_keywords: 搜索关键字
:param offset: 页数
:return: 网页源码
"""
parse = {
'aid': '24',
'app_name': 'web_search',
'offset': offset,
'format': 'json',
'keyword': search_keywords,
'autoload': 'true',
'count': 20,
'en_qc': 1,
'cur_tab': 1,
'from': 'search_tab',
'pd': 'synthesis'
}
url = 'https://www.toutiao.com/api/search/content/?' + urlencode(parse)
print(url)
try:
response = requests.get(url=url)
if response.status_code == 200:
return response.json()
else:
print('请求内容错误')
except requests.RequestException as e:
print('Error', e.args)
return None
def get_image(json):
"""
拿到图片的信息
:param json: 获取网页的json数据
:return: 图片的信息
"""
if json.get('data'):
# print(json.get('data'))
for item in json.get('data'):
if item.get('image_list'):
title = item.get('title')
images = item.get('image_list')
for image in images:
yield {
'title': title,
'image': image.get('url'),
}
def save_image(save_directory, item):
"""
保存图片
:param save_directory: 图片保存目录
:param item: 网页的json数据
:return: None
"""
content = save_directory
if not os.path.exists(content):
os.mkdir(content)
# 用图片的标题命名文件夹并替换掉不合法字符
two_level_directory = item.get('title').translate(table).replace('.', '').strip()
if not os.path.exists("{0}/{1}".format(content, two_level_directory)):
os.makedirs("{0}/{1}".format(content, two_level_directory))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
image = md5(response.content).hexdigest()
file_path = '{0}/{1}/{2}.jpg'.format(content, two_level_directory, image)
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
print(image)
f.write(response.content)
else:
print(file_path)
print('is already download')
except requests.ConnectionError as e:
print('Failed to save image: ', item.get('title'))
print('Reason: ', e.args)
def main(offset):
"""
控制分页
:param offset: 第几页
:return: None
"""
search_keywords = '街拍'
save_directory = 'Ajax爬取今日头条街拍美图'
json = get_page(search_keywords=search_keywords, offset=offset)
# print(json)
for item in get_image(json=json):
print(item)
save_image(save_directory, item=item)
GROUP_START = 0
GROUP_END = 20
if __name__ == '__main__':
pool = Pool()
groups = [x*20 for x in range(GROUP_START, GROUP_END)]
pool.map(main, groups)
pool.close()
pool.join()
# [main(x*20) for x in range(GROUP_START, GROUP_END)]
# print(os.path.dirname(__file__))
运行结果: