Scrapy是基于用Python写的一个流行的事件驱动网络框架Twisted编写的。因此,它使用非阻塞(即异步)代码实现并发。
旧版Scrapy架构图 :
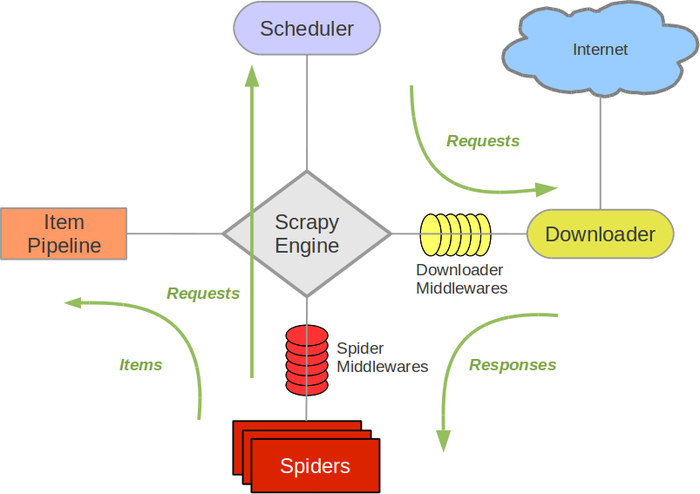
新版Scrapy架构图 :
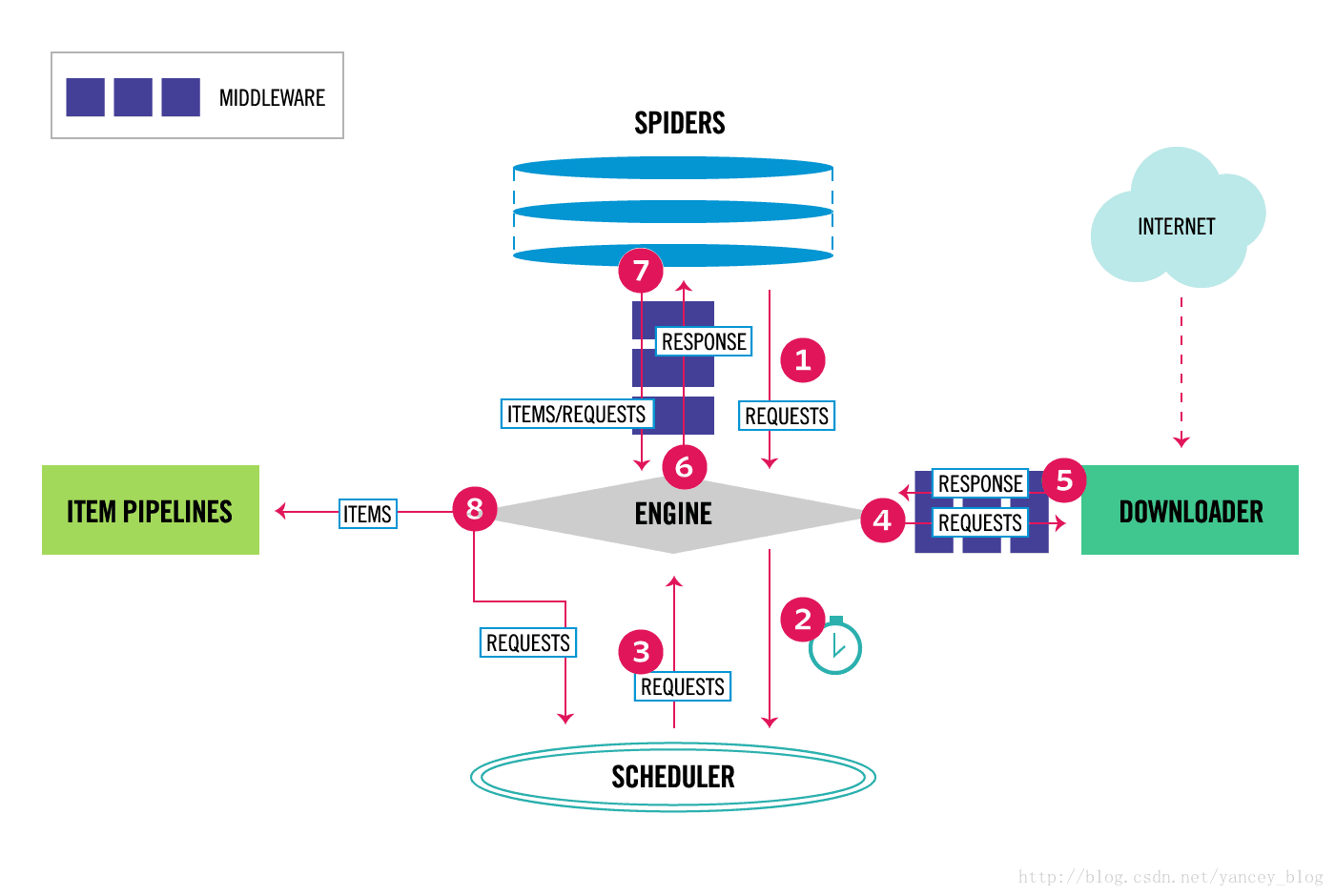
Scrapy中的数据流由执行引擎控制,如下所示:
- Engine获得从爬行器中爬行的初始请求。
- Engine在调度程序中调度请求,并请求下一次抓取请求。
- 调度程序将下一个请求返回到引擎。
- 引擎将请求发送到下载器,通过下载器中间件(请参阅process_request())。
- 页面下载完成后,下载器生成一个响应(带有该页面)并将其发送给引擎,通过下载器中间件(请参阅process_response())。
- 引擎从下载加载程序接收响应,并将其发送给Spider进行处理,并通过Spider中间件(请参阅process_spider_input())。
- Spider处理响应,并向引擎返回报废的项和新请求(要跟踪的),通过Spider中间件(请参阅process_spider_output())。
- 引擎将已处理的项目发送到项目管道,然后将已处理的请求发送到调度程序,并请求可能的下一个请求进行抓取。
- 这个过程重复(从第1步),直到调度程序不再发出请求。
Scrapy各组件介绍:
- Scrapy Engine --- Scrapy引擎 :
Scrapy Engine 负责 Spider、ItemPipeline、Downloader、Scheduler 中间的通讯,信号、数据传递等。
- Scheduler --- 调度器 :
Scheduler 负责接收 引擎 发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给 引擎。
- Downloader --- 下载器 :
Downloader 负责下载 Scrapy Engine(引擎) 发送的所有Requests请求,并将其获取得到的Responses交还给 Scrapy Engine(引擎) ,由 引擎 交给 Spider 处理,
- spider --- 爬虫 :
spider 负责处理所有的Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给 引擎,再次进入 Scheduler(调度器),
- Item Pipeline --- 项目管道 :
Item Pipeline 负责处理 Spider 中获取到的Item,并进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares --- 下载中间件 :
Downloader Middlewares 可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares --- 爬虫中间件 :
你可以理解为是一个可以自定义扩展和操作 引擎 和 Spider 中间 通信 的功能(比如进入 Spider 的Responses,和从 Spider 出去的Requesrs)
使用Spider中间件场景:
- Spider回调的后处理输出-更改/添加/删除请求或项;
- 后处理start_requests;
- 处理Spider异常;
- 对一些基于响应内容的请求调用errback而不是回调。
如果您需要执行以下操作之一,请使用下载器中间件:
- 在将请求发送到Downloader之前处理请求(即在Scrapy将请求发送到网站之前);
- 更改在传递给Spider之前收到响应;
- 发送一个新的请求,而不是将接收到的响应传递给爬行器;
- 将响应传递给Spider,而不获取web页面;
- 静静地丢掉一些请求。
Scrapy的运作流程 :
代码写好,程序开始运行 ...
- 引擎 :Hi!Spider ,你要处理哪一 个网站?
- Spider :老大要我处理 xxx .com.T
- 引擎 :你把第一个需要处理的URL给我吧。
- Spider :给你,第一个URL是 xxxxxx .com。
- 引擎 :Hi!调度器,我这有request请求你帮我排序入队一下。
- 调度器 :好的,正在处理你等一下。
- 引擎 :Hi!调度器 ,把你处理好的request请求给我。
- 调度器 :给你,这是我处理好的request
- 引擎 :Hi!下载器,你按照老大的 下载中间件 的设置帮我下载一下这个request请求
- 下载器 :好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后 引擎 告诉 调度器 ,这个request下载失败了,你记录一下,我们待会儿再下载)
- 引擎 :Hi!Spider,这是下载好的东西,并且已经按照老大的 下载中间件 处理过了,你自己处理一 下
(注意!这儿responses默认是交给 def parse() 这个函数处理的)
制作Scrapy爬虫 一共需要4步:
- 新建项目 (scrapyQtartproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容( (pipelines.py):设计管道存储爬取内容