运行环境: python 3.6.0 今天处于练习的目的,就用 python 写了一个百度翻译,是如何做到的呢,其实呢就是拿到接口,通过这个接口去访问,不过中间确实是出现了点问题,不过都解决掉了 先晾图后晾代码 运行结果: 代码:
运行环境:Windows 操作系统 (本人 Windows 10 x64) 1、下载zip安装包: MySQL8.0 For Windows zip包下载地址:https://dev.mysql.com/downloads/file/?id=485812,进入页面后可以不用登录。后点击底部“No thanks, just start my download.”即可开始下载。
Scrapy是基于用Python写的一个流行的事件驱动网络框架Twisted编写的。因此,它使用非阻塞(即异步)代码实现并发。 Scrapy中的数据流由执行引擎控制,如下所示: Engine获得从爬行器中爬行的初始请求。 Engine在调度程序中调度请求,并请求下一次抓取请求。 调度程序将下一个请求返回到引擎。
selenium登陆淘宝的滑动怎么过,确实淘宝在滑动这一块限制了很多条件 没太多废话,上效果,在分析过程,上传code 由于现在大型网站对selenium工具进行检测,若检测到selenium,则判定为机器人,访问被拒绝。所以第一步是要防止被检测出为机器人,如何防止被检测到呢?当使用selenium进行自动化操作时,在chrome浏览器中的consloe中输入
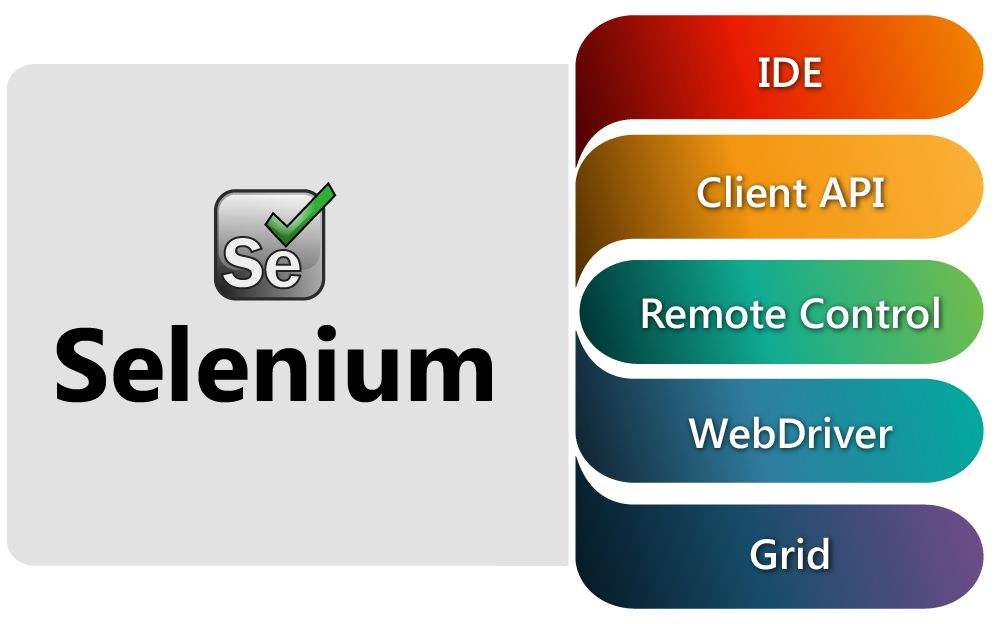
selenium 是一个很友好的网站调试工具,但是很多人都用来做爬虫,其实我也是用来做爬虫,毕竟好东西要共享,哈哈 在做静态网页的请求的时候,普通的http/https可以很轻松的搞定,但是面对动态网页,很多内容都是通过后面的js加载出来的,如果还要用协议解决,希望你遇到的问题可以解决。 在爬虫这一块,很多反爬虫对方对selenium并不是太友好