-
 Linux论坛
Linux论坛
-
 伟大的夜幕团队
伟大的夜幕团队
-
 Golang社区
Golang社区
-
 MySQL论坛
MySQL论坛
推荐阅读
windows系统下redis安装以及设置redis开机自启动方法教程
一、下载redis 官网上下载过程容易出现问题,建议到github上面下载,下载完之后直接解压缩即可用 https://github.com/Mi...
如何用windows通过python3建立最简单的服务器
今天来介绍一下如何用Python3的内置模块搭建一个简单的服务器,Python自带有服务模块 而且python3相比于python2有很大不同之处,...
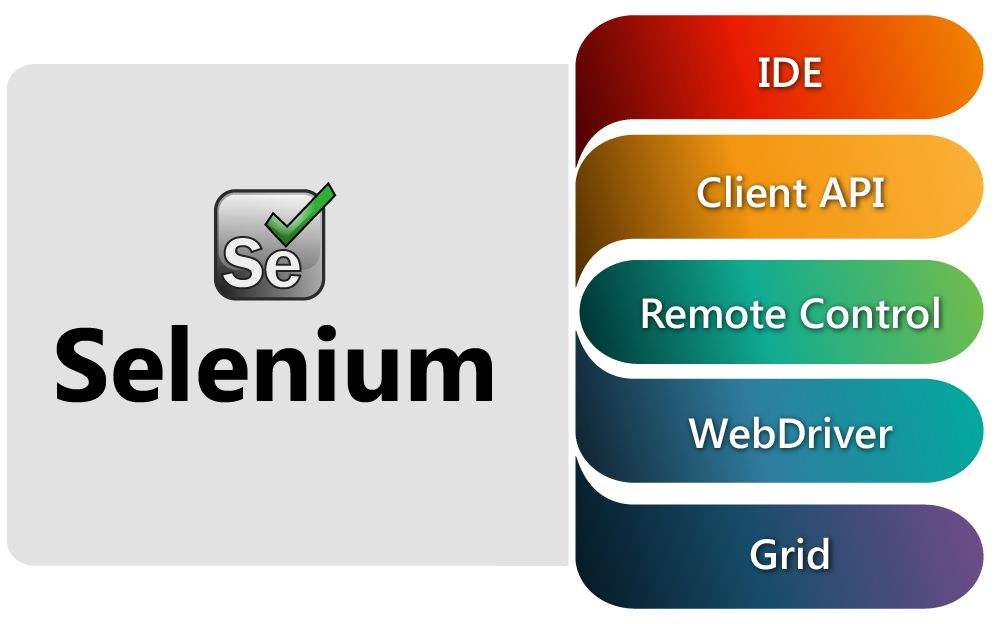
Selenium操作Firefox无界面浏览器
之前做爬虫的时候经常需要selenium模拟,我经常用的是Firefox和Chrome浏览器,但是在使用的时候总是会打开浏览器才能正常抓取数据,无奈之下...